Connect Streamlit to TigerGraph
Introduction
This guide explains how to securely access a TigerGraph database from Streamlit Community Cloud. It uses the pyTigerGraph library and Streamlit's Secrets management.
Create a TigerGraph Cloud Database
First, follow the official tutorials to create a TigerGraph instance in TigerGraph Cloud, either as a blog or a video. Note your username, password, and subdomain.
For this tutorial, we will be using the COVID-19 starter kit. When setting up your solution, select the “COVID-19 Analysis" option.
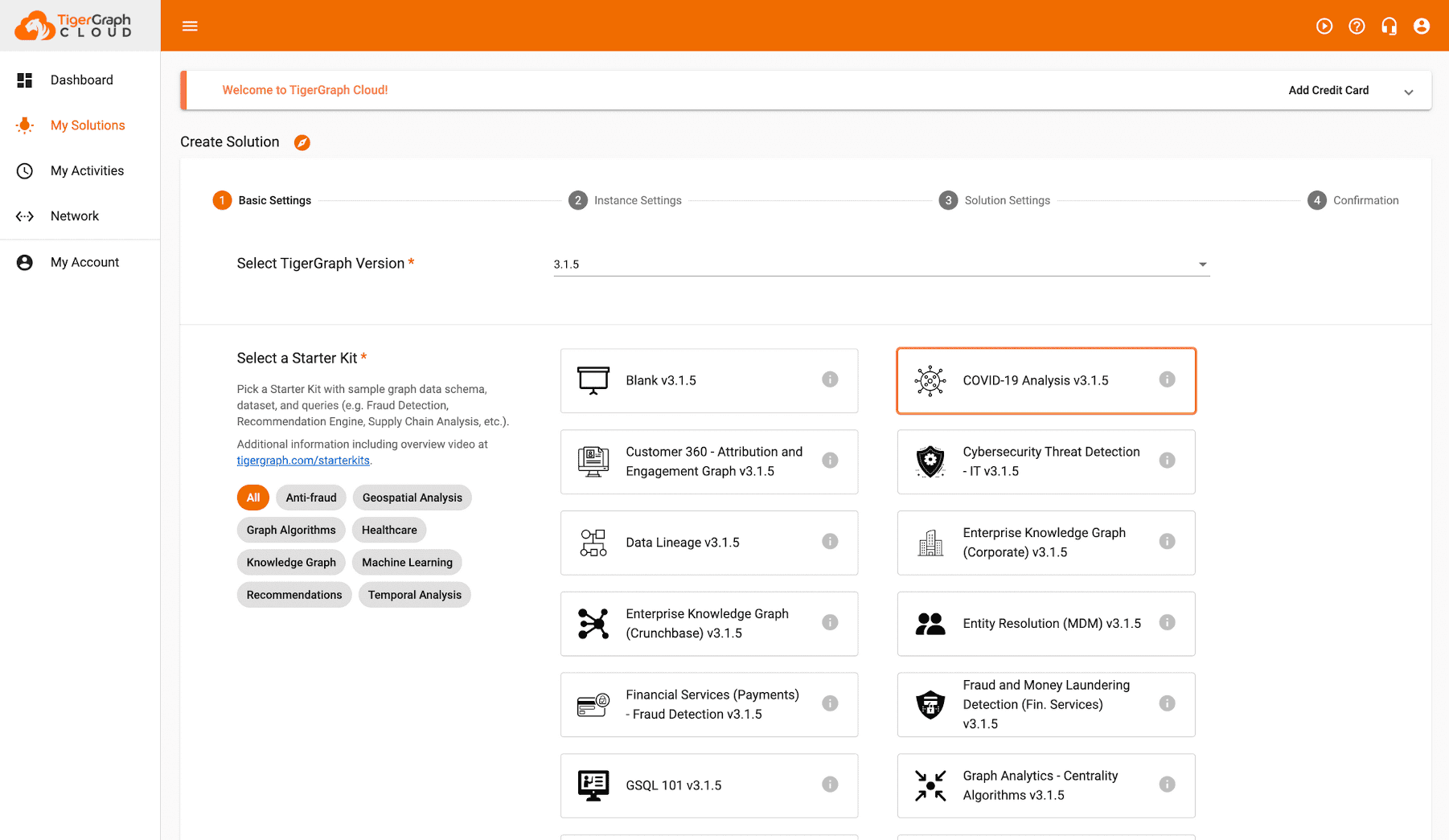
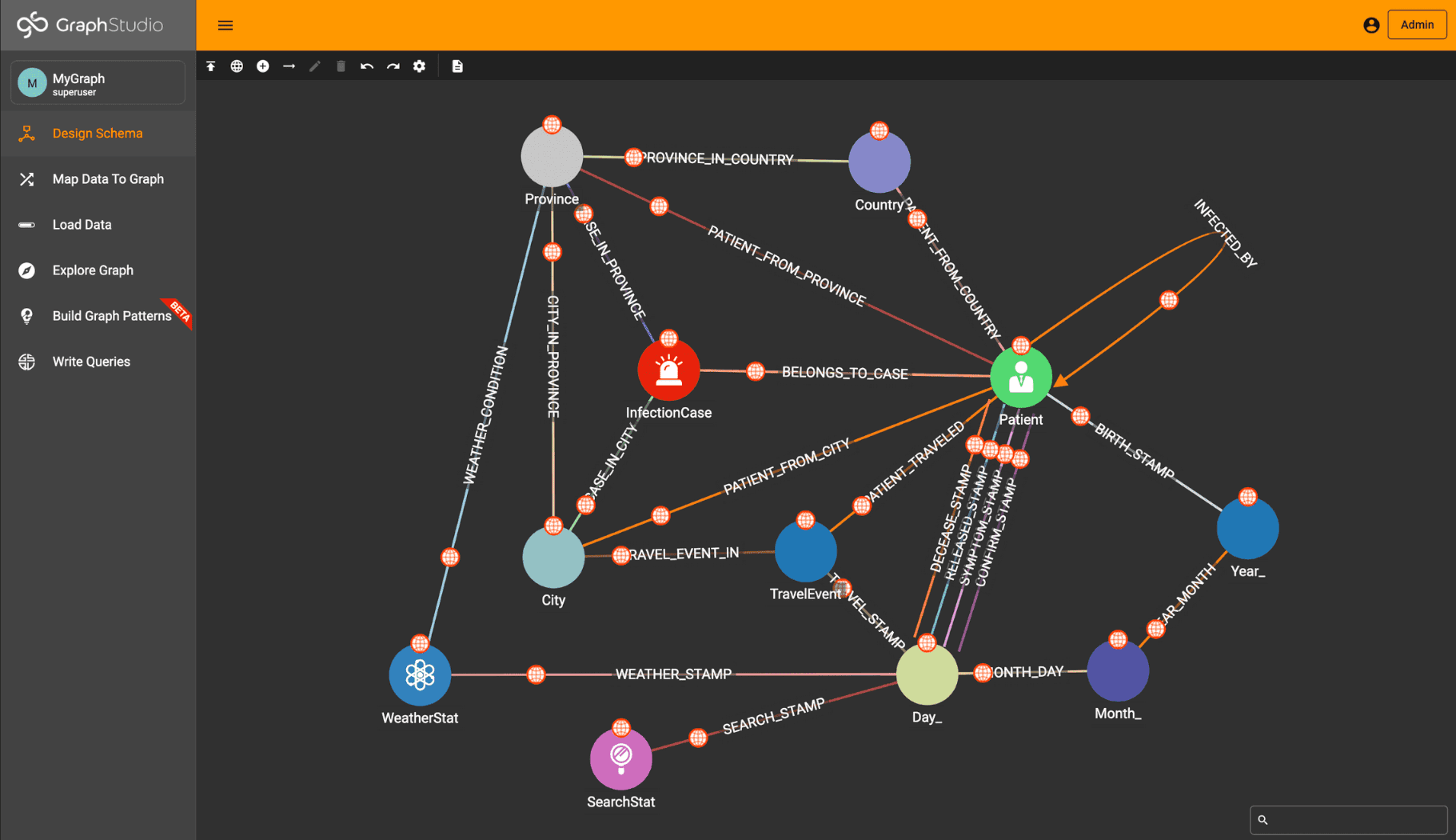
Once it is started, ensure your data is downloaded and queries are installed.
Add username and password to your local app secrets
Your local Streamlit app will read secrets from a file .streamlit/secrets.toml in your app’s root directory. Create this file if it doesn’t exist yet and add your TigerGraph Cloud instance username, password, graph name, and subdomain as shown below:
# .streamlit/secrets.toml
[tigergraph]
host = "https://xxx.i.tgcloud.io/"
username = "xxx"
password = "xxx"
graphname = "xxx"
Important
Add this file to .gitignore and don't commit it to your GitHub repo!
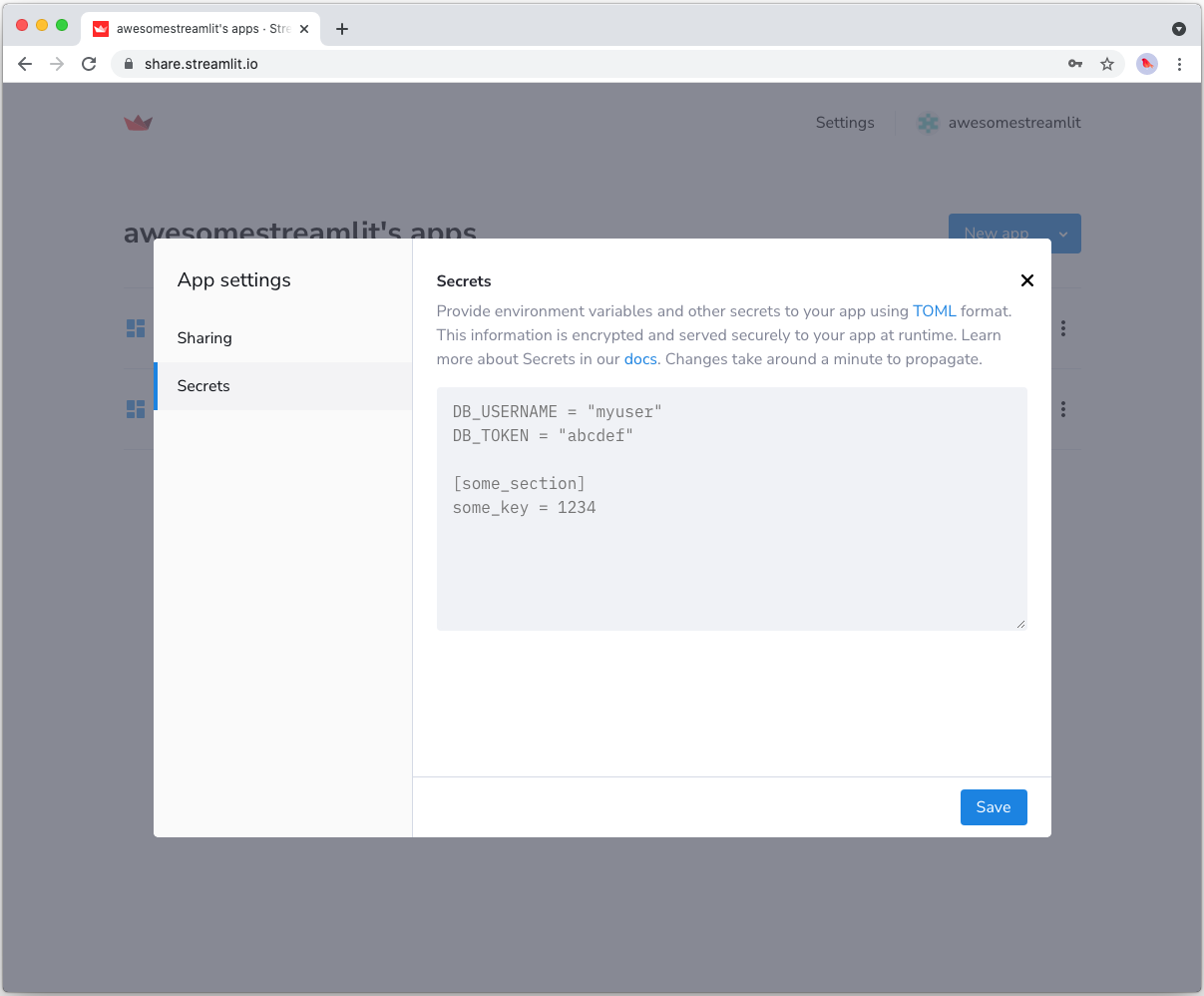
Copy your app secrets to the cloud
As the secrets.toml file above is not committed to GitHub, you need to pass its content to your deployed app (on Streamlit Community Cloud) separately. Go to the app dashboard and in the app's dropdown menu, click on Edit Secrets. Copy the content of secrets.toml into the text area. More information is available at Secrets management.
Add PyTigerGraph to your requirements file
Add the pyTigerGraph package to your requirements.txt file, preferably pinning its version (replace x.x.x with the version you want installed):
# requirements.txt
pyTigerGraph==x.x.x
Write your Streamlit app
Copy the code below to your Streamlit app and run it. Make sure to adapt the name of your graph and query.
# streamlit_app.py
import streamlit as st
import pyTigerGraph as tg
# Initialize connection.
conn = tg.TigerGraphConnection(**st.secrets["tigergraph"])
conn.apiToken = conn.getToken(conn.createSecret())
# Pull data from the graph by running the "mostDirectInfections" query.
# Uses st.cache_data to only rerun when the query changes or after 10 min.
@st.cache_data(ttl=600)
def get_data():
most_infections = conn.runInstalledQuery("mostDirectInfections")[0]["Answer"][0]
return most_infections["v_id"], most_infections["attributes"]
items = get_data()
# Print results.
st.title(f"Patient {items[0]} has the most direct infections")
for key, val in items[1].items():
st.write(f"Patient {items[0]}'s {key} is {val}.")
See st.cache_data above? Without it, Streamlit would run the query every time the app reruns (e.g. on a widget interaction). With st.cache_data, it only runs when the query changes or after 10 minutes (that's what ttl is for). Watch out: If your database updates more frequently, you should adapt ttl or remove caching so viewers always see the latest data. Learn more in Caching.
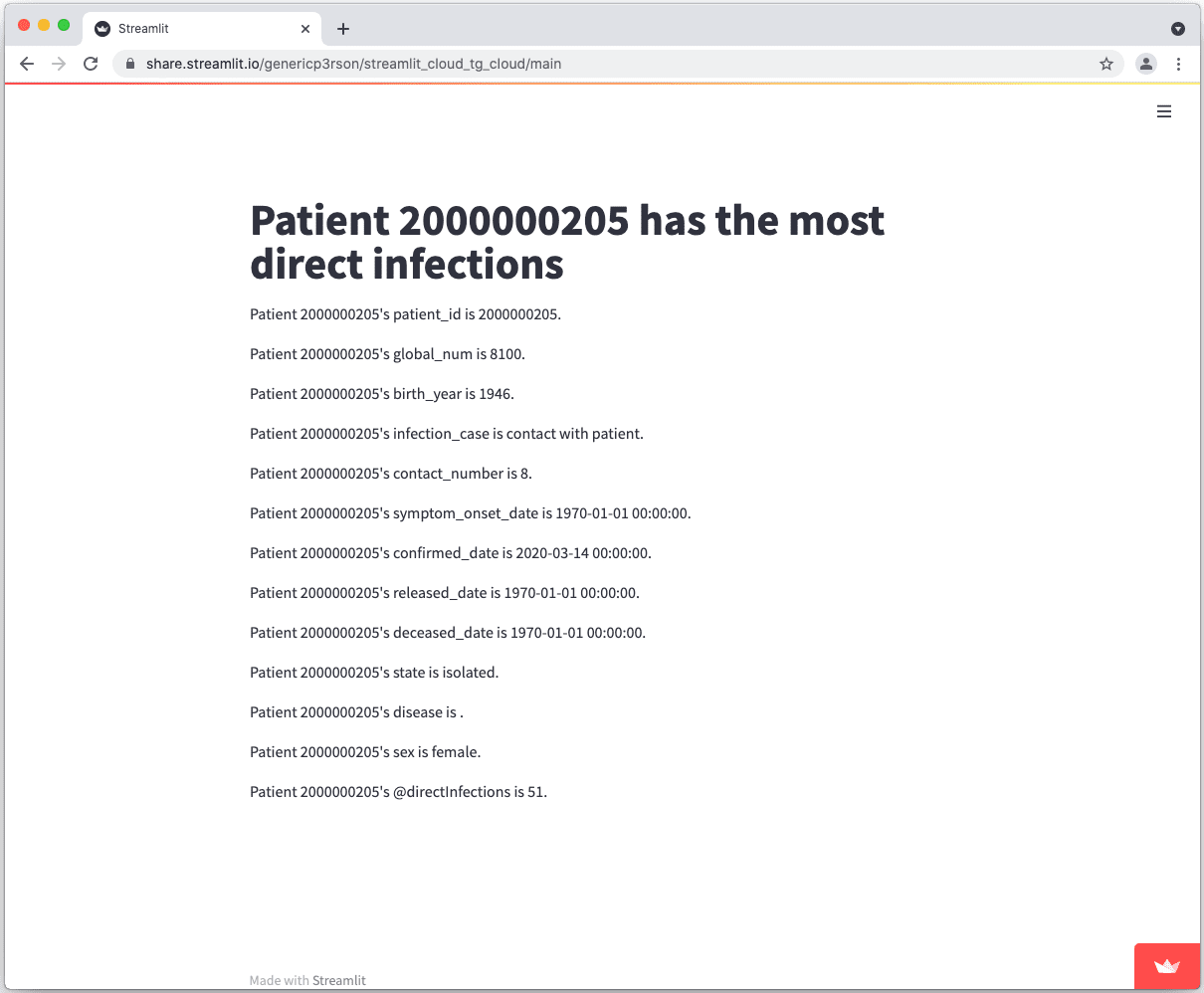
If everything worked out (and you used the example data we created above), your app should look like this:
Still have questions?
Our forums are full of helpful information and Streamlit experts.