Connect Streamlit to Google BigQuery
Introduction
This guide explains how to securely access a BigQuery database from Streamlit Community Cloud. It uses the google-cloud-bigquery library and Streamlit's Secrets management.
Create a BigQuery database
Note
If you already have a database that you want to use, feel free to skip to the next step.
For this example, we will use one of the sample datasets from BigQuery (namely the shakespeare table). If you want to create a new dataset instead, follow Google's quickstart guide.
Enable the BigQuery API
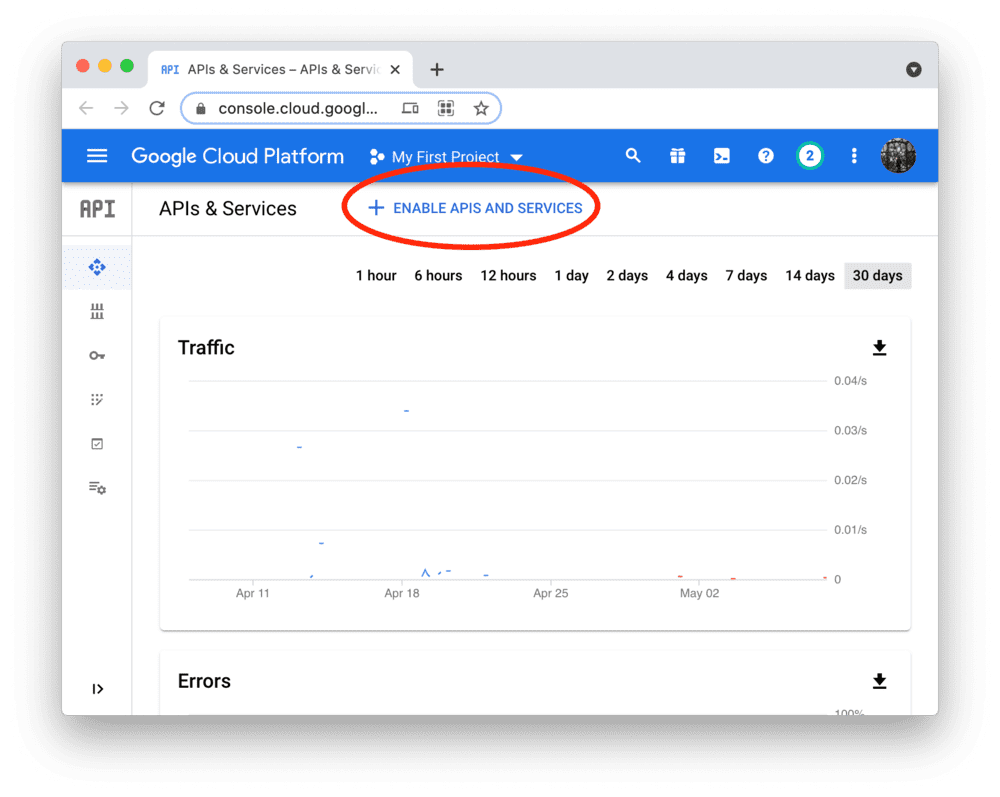
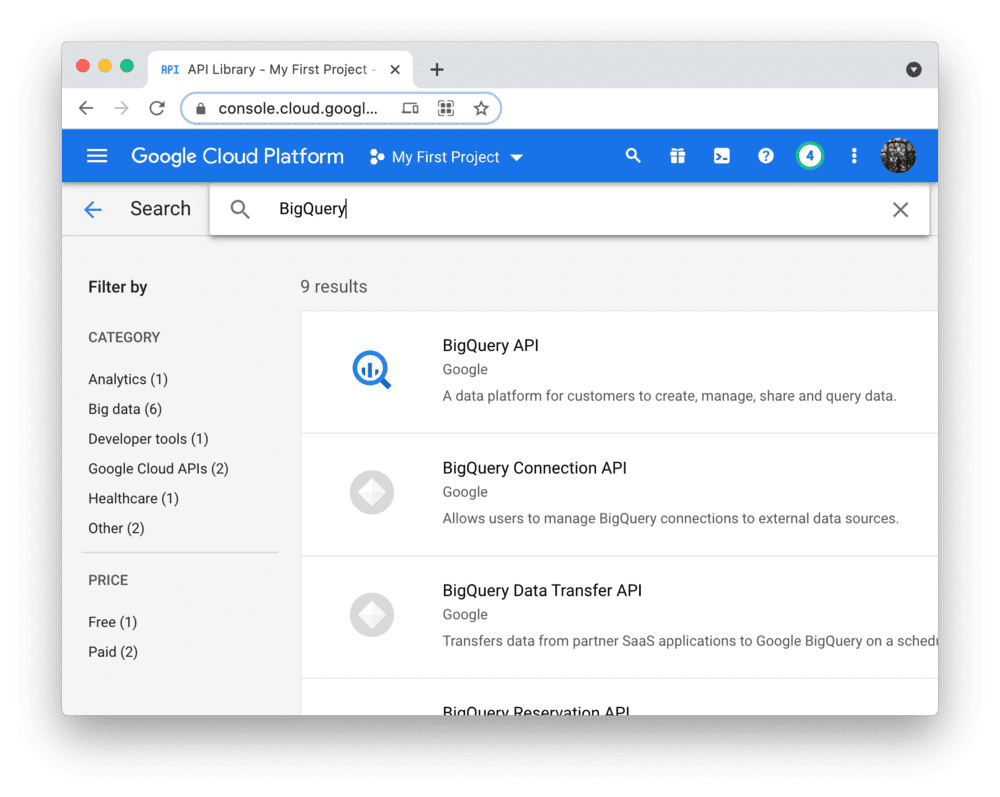
Programmatic access to BigQuery is controlled through Google Cloud Platform. Create an account or sign in and head over to the APIs & Services dashboard (select or create a project if asked). As shown below, search for the BigQuery API and enable it:

Create a service account & key file
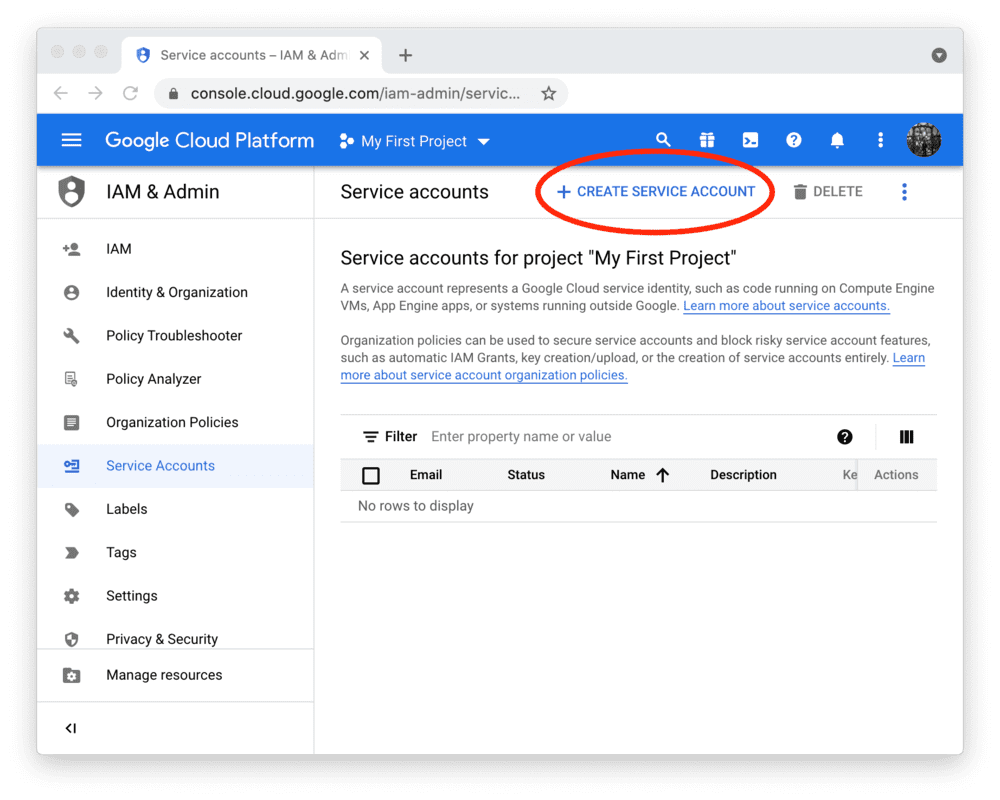
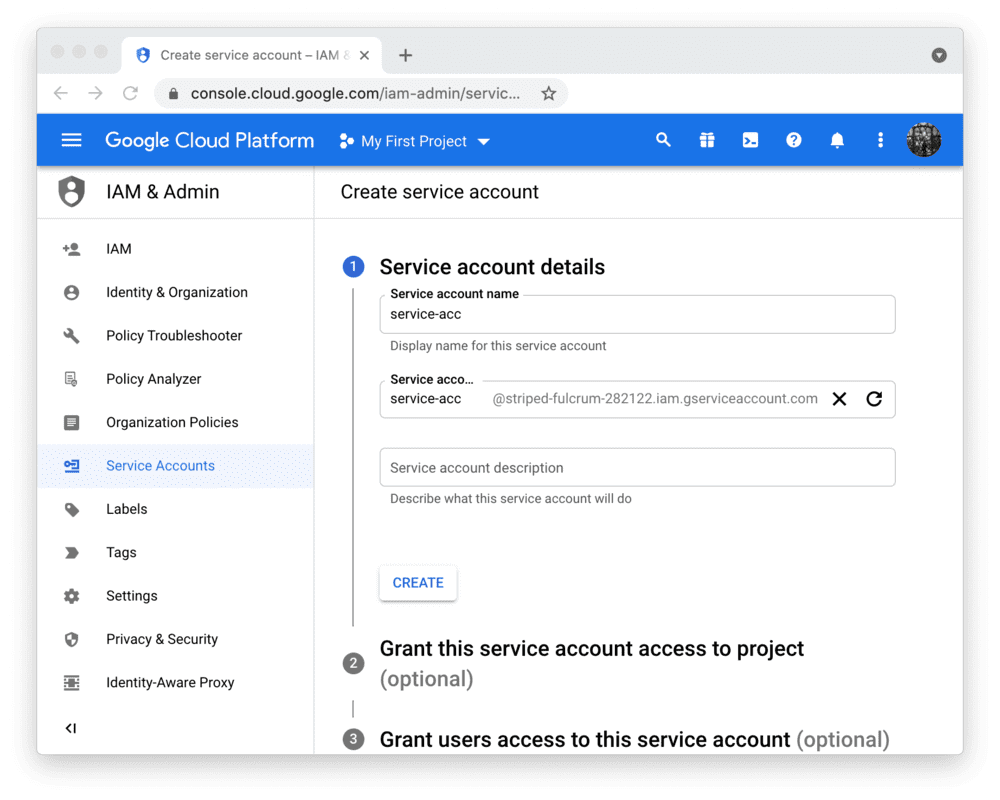
To use the BigQuery API from Streamlit Community Cloud, you need a Google Cloud Platform service account (a special account type for programmatic data access). Go to the Service Accounts page and create an account with the Viewer permission (this will let the account access data but not change it):
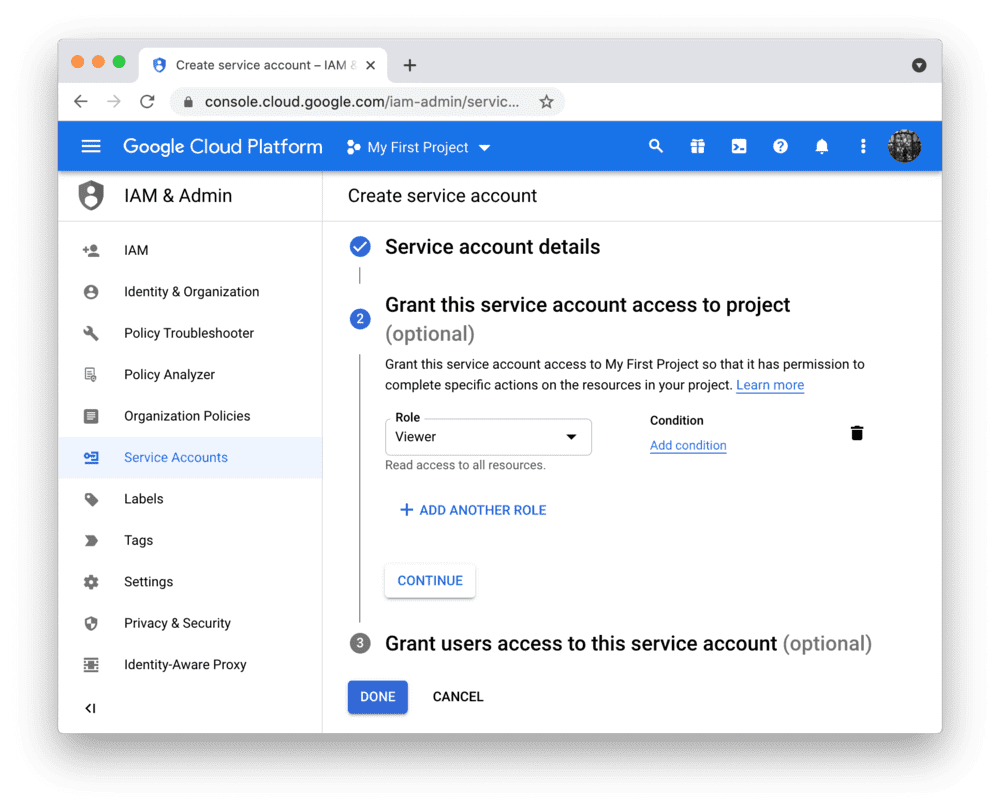
Note
If the button CREATE SERVICE ACCOUNT is gray, you don't have the correct permissions. Ask the admin of your Google Cloud project for help.
After clicking DONE, you should be back on the service accounts overview. Create a JSON key file for the new account and download it:
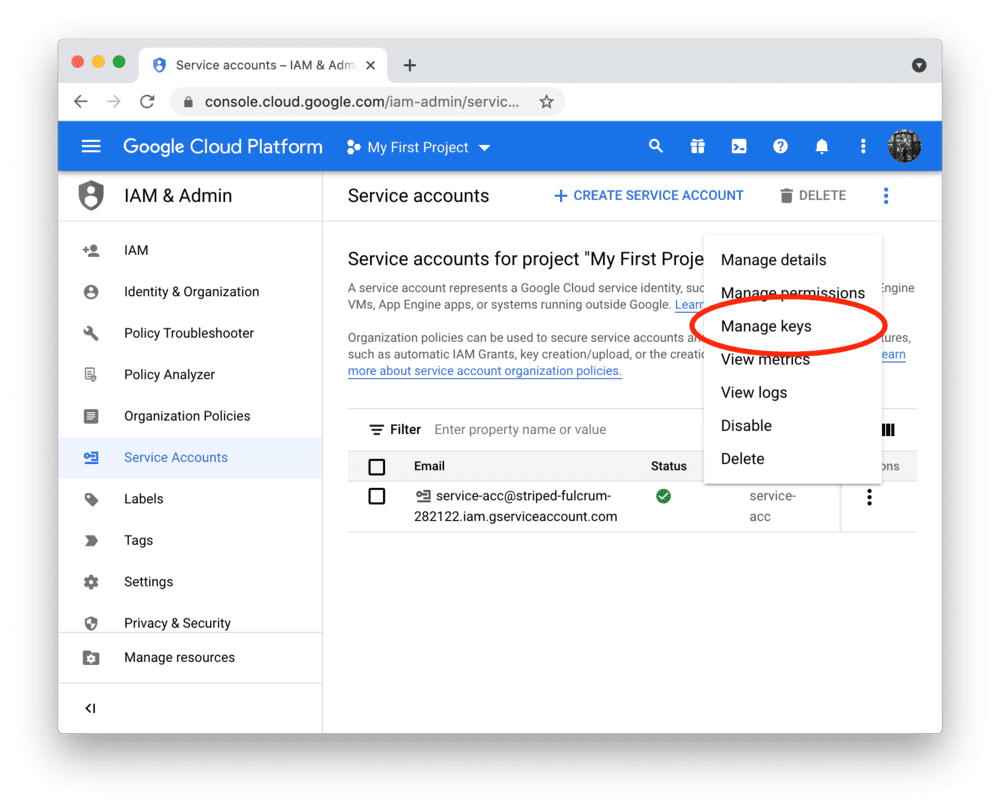
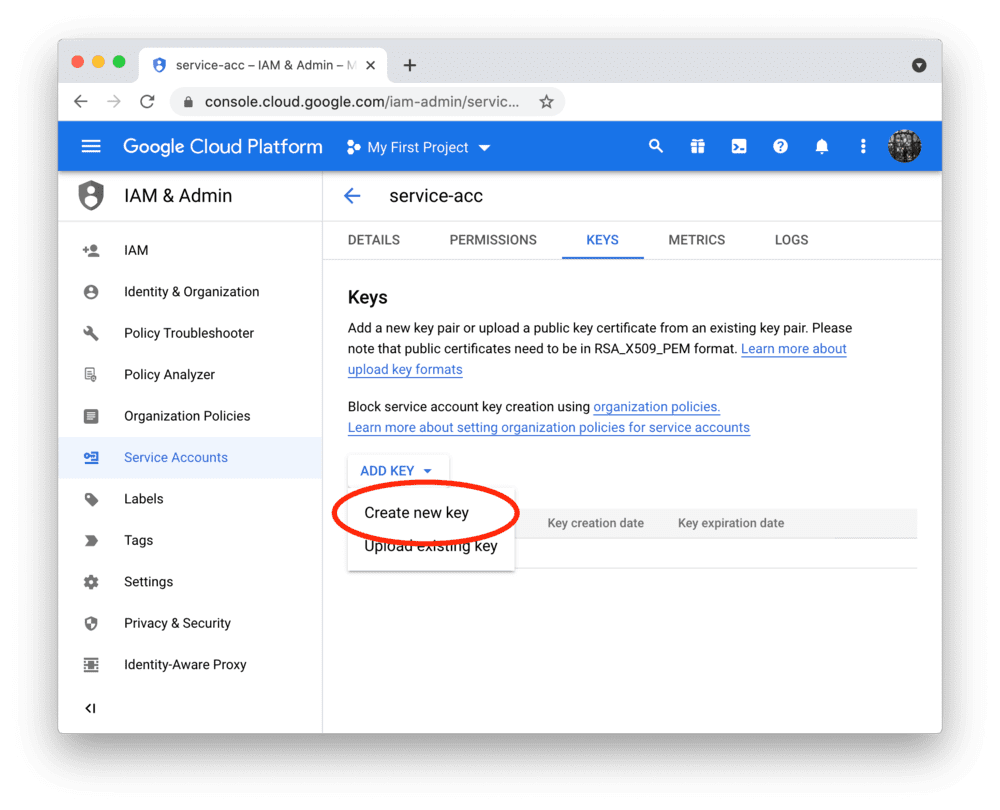
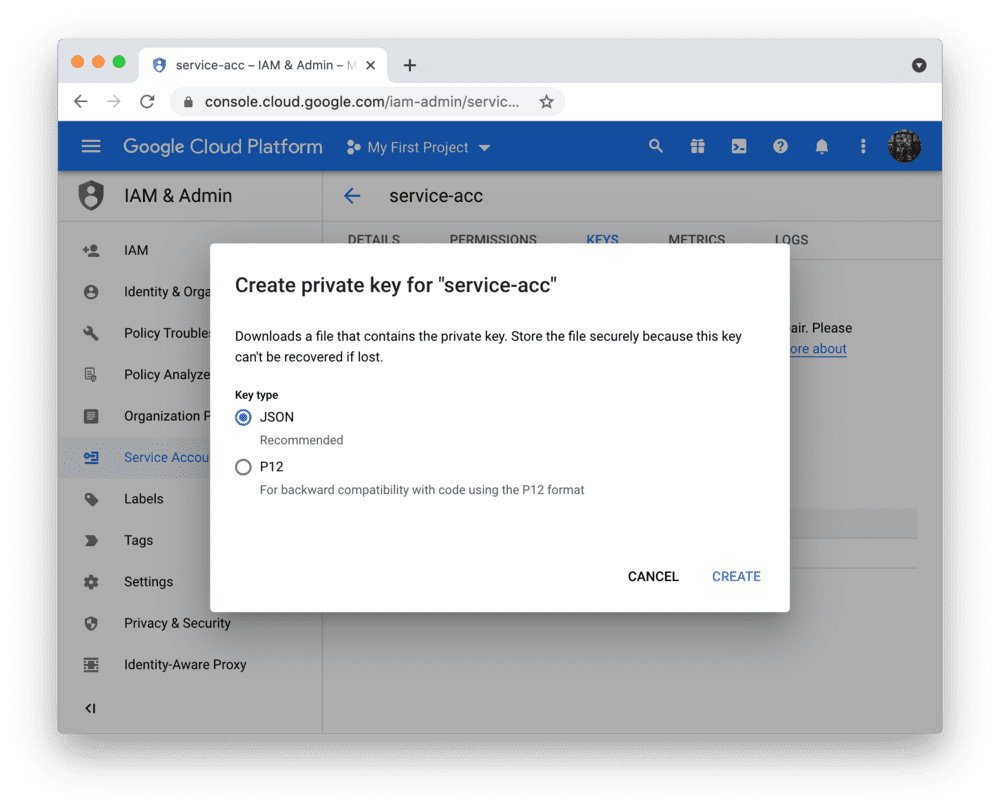
Add the key file to your local app secrets
Your local Streamlit app will read secrets from a file .streamlit/secrets.toml in your app's root
directory. Create this file if it doesn't exist yet and add the content of the key file you just
downloaded to it as shown below:
Important
Add this file to .gitignore and don't commit it to your GitHub repo!
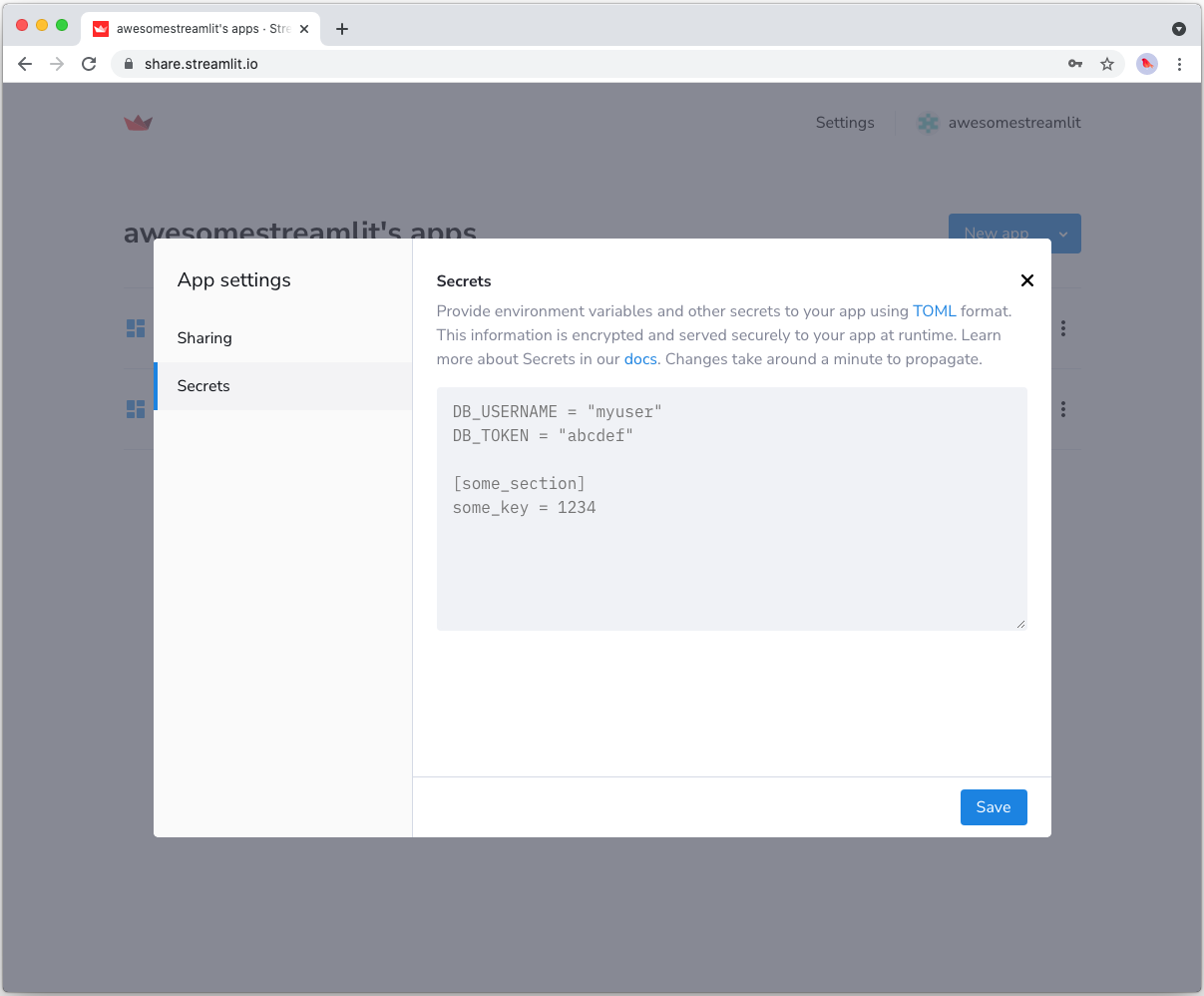
Copy your app secrets to the cloud
As the secrets.toml file above is not committed to GitHub, you need to pass its content to your deployed app (on Streamlit Community Cloud) separately. Go to the app dashboard and in the app's dropdown menu, click on Edit Secrets. Copy the content of secrets.toml into the text area. More information is available at Secrets management.
Add google-cloud-bigquery to your requirements file
Add the google-cloud-bigquery package to your requirements.txt file, preferably pinning its version (replace x.x.x with the version want installed):
Write your Streamlit app
Copy the code below to your Streamlit app and run it. Make sure to adapt the query if you don't use the sample table.
See st.cache_data above? Without it, Streamlit would run the query every time the app reruns (e.g. on a widget interaction). With st.cache_data, it only runs when the query changes or after 10 minutes (that's what ttl is for). Watch out: If your database updates more frequently, you should adapt ttl or remove caching so viewers always see the latest data. Learn more in Caching.
Alternatively, you can use pandas to read from BigQuery right into a dataframe! Follow all the above steps, install the pandas-gbq library (don't forget to add it to requirements.txt!), and call pandas.read_gbq(query, credentials=credentials). More info in the pandas docs.
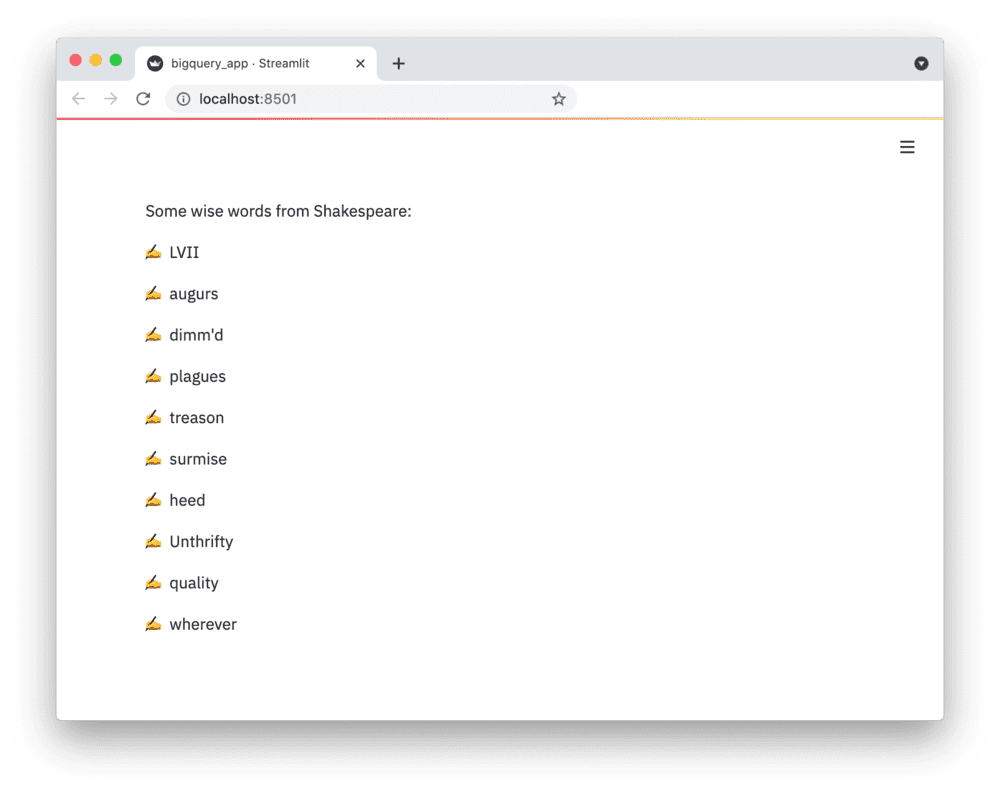
If everything worked out (and you used the sample table), your app should look like this:
Still have questions?
Our forums are full of helpful information and Streamlit experts.